
Auto Caption 跨平台的实时字幕显示软件
软件简介
Auto Caption 是一个跨平台的字幕显示软件,能够实时获取系统音频输入(录音)或输出(播放声音)的流式数据,并调用音频转文字的模型生成对应音频的字幕。软件提供的默认字幕引擎(使用阿里云 Gummy 模型)支持九种语言(中、英、日、韩、德、法、俄、西、意)的识别与翻译。
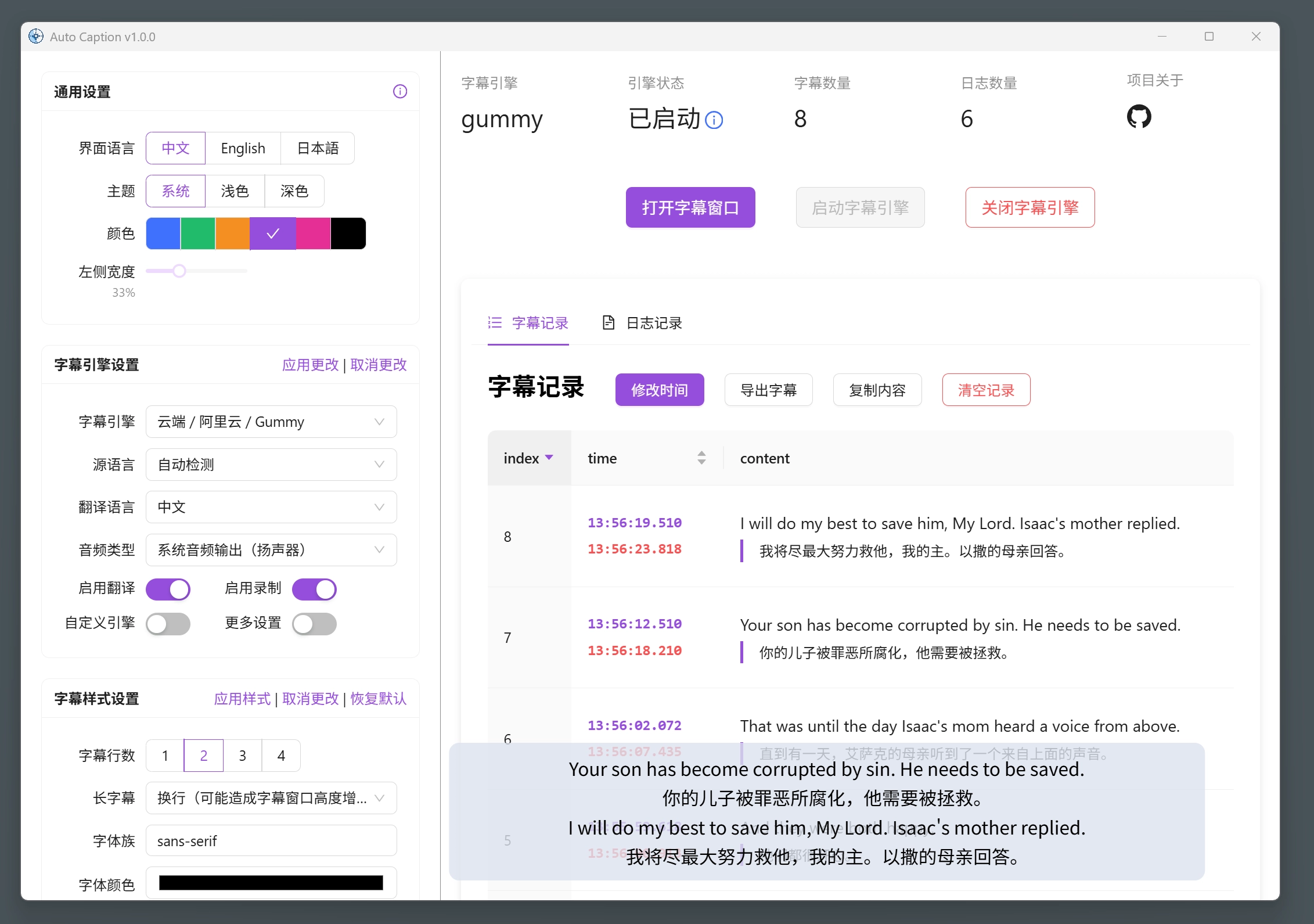
目前软件默认字幕引擎在 Windows、 macOS 和 Linux 平台下均拥有完整功能,在 macOS 要获取系统音频输出需要额外配置。
测试过可正常运行的操作系统信息如下,软件不能保证在非下列版本的操作系统上正常运行。
软件缺点
要使用默认的 Gummy 字幕引擎需要获取阿里云的 API KEY。
在 macOS 平台获取音频输出需要额外配置。
软件使用 Electron 构建,因此软件体积不可避免的较大。
Gummy 引擎使用前准备
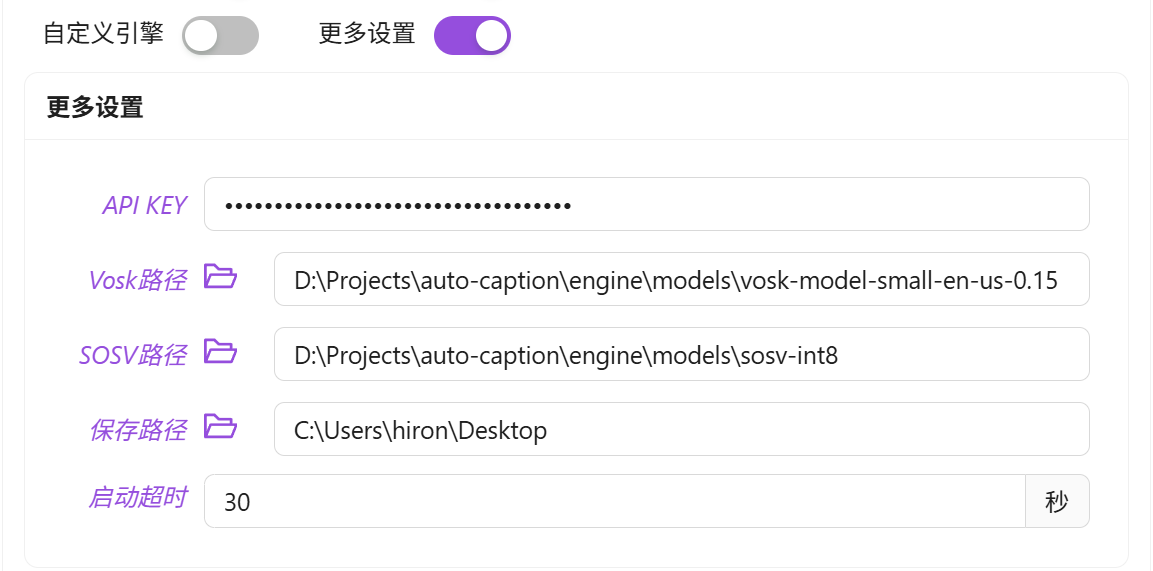
要使用软件提供的默认字幕引擎(阿里云 Gummy),需要从阿里云百炼平台获取 API KEY,然后将 API KEY 添加到软件设置中或者配置到环境变量中(仅 Windows 平台支持读取环境变量中的 API KEY)。
国际版的阿里云服务并没有提供 Gummy 模型,因此目前非中国用户无法使用默认字幕引擎。
Vosk 引擎使用前准备
如果要使用 Vosk 本地字幕引擎,首先需要在 Vosk Models(https://alphacephei.com/vosk/models)页面下载你需要的模型。然后将下载的模型安装包解压到本地,并将对应的模型文件夹的路径添加到软件的设置中。
使用 SOSV 模型
使用 SOSV 模型的方式和 Vosk 一样
软件使用
修改设置
字幕设置可以分为三类:通用设置、字幕引擎设置、字幕样式设置。需要注意的是,修改通用设置是立即生效的。但是对于其他两类设置,修改后需要点击对应设置模块右上角的“应用”选项,更改才会真正生效。如果点击“取消更改”那么当前修改将不会被保存,而是回退到上次修改的状态。
启动和关闭字幕
在修改完全部配置后,点击界面的“启动字幕引擎”按钮,即可启动字幕。如果需要独立的字幕展示窗口,单击界面的“打开字幕窗口”按钮即可激活独立的字幕展示窗口。如果需要暂停字幕识别,单击界面的“关闭字幕引擎”按钮即可。
调整字幕展示窗口
如下图为字幕展示窗口,该窗口实时展示当前最新字幕。窗口右上角三个按钮的功能分别是:将窗口固定在最前面、打开字幕控制窗口、关闭字幕展示窗口。该窗口宽度可以调整,将鼠标移动至窗口的左右边缘,拖动鼠标即可调整宽度。
字幕记录的导出
在字幕控制窗口中可以看到当前收集的所有字幕的记录,点击“导出字幕”按钮,即可将字幕记录导出为 JSON 或 SRT 文件。
字幕引擎
所谓的字幕引擎实际上是一个子程序,它会实时获取系统音频输入(录音)或输出(播放声音)的流式数据,并调用音频转文字的模型生成对应音频的字幕。生成的字幕通过转换为字符串的 JSON 数据,并通过标准输出传递给主程序。主程序读取字幕数据,处理后显示在窗口上。
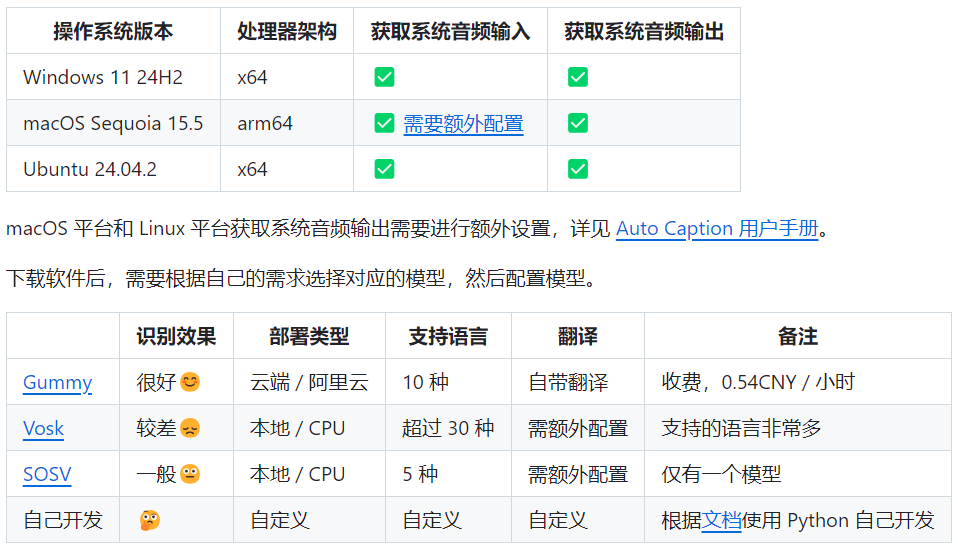
软件提供了两个默认的字幕引擎,如果你需要其他的字幕引擎,可以通过打开自定义引擎选项来调用其他字幕引擎(其他引擎需要针对该软件进行开发)。其中引擎路径是自定义字幕引擎在你的电脑上的路径,引擎指令是自定义字幕引擎的运行参数,这部分需要按该字幕引擎的规则进行填写。
注意使用自定义字幕引擎时,前面的字幕引擎的设置将全部不起作用,自定义字幕引擎的配置完全通过引擎指令进行配置。
特性
生成音频输出或麦克风输入的字幕
支持调用本地 Ollama 模型或云端 Google 翻译 API 进行翻译
跨平台(Windows、macOS、Linux)、多界面语言(中文、英语、日语)支持
丰富的字幕样式设置(字体、字体大小、字体粗细、字体颜色、背景颜色等)
灵活的字幕引擎选择(阿里云 Gummy 云端模型、本地 Vosk 模型、本地 SOSV 模型、还可以自己开发模型)
多语言识别与翻译(自带字幕引擎说明”)
字幕记录展示与导出(支持导出 .srt 和 .json 格式)
基本使用
软件已经适配了 Windows、macOS 和 Linux 平台。
字幕引擎介绍
所谓的字幕引擎实际上是一个子程序,它会实时获取系统音频输入(麦克风)或输出(扬声器)的流式数据,并调用音频转文字的模型生成对应音频的字幕。生成的字幕转换为 JSON 格式的字符串数据,并通过标准输出传递给主程序(需要保证主程序读取到的字符串可以被正确解释为 JSON 对象)。主程序读取并解释字幕数据,处理后显示在窗口上。
字幕引擎进程和 Electron 主进程之间的通信遵循的标准为:caption engine api-doc。
运行流程
主进程和字幕引擎通信的流程:
启动引擎
Electron 主进程:使用 child_process.spawn() 启动字幕引擎进程
字幕引擎进程:创建 TCP Socket 服务器线程,创建后在标准输出中输出转化为字符串的 JSON 对象,该对象中包含 command 字段,值为 connect
主进程:监听字幕引擎进程的标准输出,尝试将标准输出按行分割,解析为 JSON 对象,并判断对象的 command 字段值是否为 connect,如果是则连接 TCP Socket 服务器
字幕识别
字幕引擎进程:新建线程监听系统音频输出,将获取的音频数据块放入共享队列中(shared_data.chunk_queue)。字幕引擎不断读取共享队列中的音频数据块并解析。字幕引擎还可能新建线程执行翻译操作。最后字幕引擎通过标准输出发送解析的字幕数据对象字符串
Electron 主进程:持续监听字幕引擎的标准输出,并根据解析的对象的 command 字段采取不同的操作
关闭引擎
Electron 主进程:当用户在前端操作关闭字幕引擎时,主进程通过 Socket 通信给字幕引擎进程发送 command 字段为 stop 的对象字符串
字幕引擎进程:接收主引擎进程发送的字幕数据对象字符串,将字符串解析为对象,如果对象的 command 字段为 stop,则将全局变量 shared_data.status 的值设置为 stop
字幕引擎进程:主线程循环监听系统音频输出,当 thread_data.status 的值不为 running 时,则结束循环,释放资源,结束运行
Electron 主进程:如果检测到字幕引擎进程结束,进行相应处理,并向前端反馈
免责声明
本站提供的所有信息、教程、软件版权归原公司所有,仅供日常学习和研究使用,不得用于任何商业用途,下载试用后请24小时内删除,因下载本站资源造成的损失,全部由使用者本人承担!如有侵权、不妥之处,请第一时间联系我们删除!
本站如果侵犯你的利益,携带权利证明请发送邮箱到 admin@pan.kim,我们会很快的为您处理。